Multiple Steps vs Separate Jobs
Generally, if two tasks will always be executed together in the same sequence, they should be part of the same job. If the tasks sometimes need to run separately, or in a different order, or as part of a different sequence, they should be in separate jobs.
adTempus allows you to group related tasks into a single job, using multiple steps within the job. Grouping tasks this way simplifies administration of adTempus, because you have fewer jobs to administer, and the relationship between the tasks is clear.
In most cases the two approaches are equivalent and interchangeable. For example, the following setups both accomplish the same result:
|
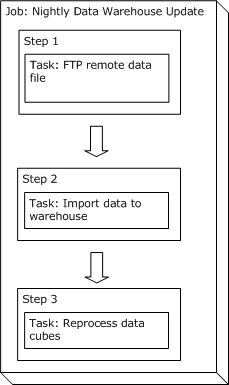
Multiple steps within the same job
|
Separate jobs, connected using Job Control actions
|

There is, however, one key difference between steps and jobs that may require you to use multiple jobs: steps within a job execute sequentially, one at a time. That is, within a job only one step may be executing at any given time. Jobs, on the other hand, can execute in parallel: any number of jobs can be executing at once.
To illustrate the ramifications we'll add one more task to our data warehouse update example. We currently have the following steps:
- Download a data file using FTP.
- Load the downloaded data into the data warehouse.
- Run the process that reprocesses the data warehouse and rebuilds the data cubes
Now we'll add a new task before task 3:
- Download a data file using FTP.
- Load the downloaded data into the data warehouse.
- Extract data from a local database and copy it to the data warehouse.
- Run the process that reprocesses the data warehouse and rebuilds the data cubes.
 We have the following dependencies among the tasks:
We have the following dependencies among the tasks:
- Task 2 must follow task 1.
- Task 3 can execute independently of tasks 1 and 2.
- Task 4 must follow tasks 2 and 3.
Since task 3 is not dependent on tasks 1 and 2, it makes sense to have it execute concurrently with tasks 1 and 2—there's no need to wait until they're finished.
To do this, we must move this task to a separate job. We then link the two jobs together as follows:
- An action attached to the "Job Start" event on our original job starts the local extraction job. That is, whenever the main job is started, the second job is started as well.
- Step 3 of the main job does the data warehouse reprocessing. Step 3 will be automatically started once Step 2 (which imports the downloaded data) completes. However, we need for Step 3 to wait until the local data extract (executing in the secondary job) completes. So we add a Job Condition to Step 3, causing it to wait until the secondary job completes.
